Image Credit: https://exxactcorp.com/
GPU Kernels
So how do we actually program these chips? Do they run normal assembly we can compile to from the langauges we already use? Unfortunately not. Hardware manufactureres have created custom languages programmers use to write little programs that get parallelized on the hardware called kernels. An example kernel to do many additions in parallel on Nvidia GPUs might look like this:a and b, which are float arrays. We get the index of the current thread using blockIdx, blockDim, and threadIdx, and use that to index into the input and output arrays.
This kernel gets ran for each element of the input arrays, all in parallel.
Compiler flow
The typical approach in Luminal for supporting new backends would be:- Swap out each primitive operation with a backend-specific operation.
- Add in operations to copy to device and copy from device before and after Function operations.
- Pattern-match to swap out chunks of operations with specialized variants.
- All other optimizations.
Step 1: Metal Primops
We want to generically support all possible models in Luminal, so our first step is to replicate all primitive operations with a Metal version. Since there are 12 primitive operations, we need 12 Metal ops. You can see these incrates/luminal_metal/src/prim.rs. The compiler simply loops through all ops in the graph and swaps them out with the Metal variant.
These primitive operations are very simple. Here’s the MetalExp2 op, slightly simplified for clarity:
Step 2: Moving data around
Since our data always starts on the host device (normal RAM), we need to move it to GPU memory. This means we need to look at the remaining ops that produce data from the host, and insert a CopyToDevice op, and look at where we need to get data back to host and insert a CopyFromDevice op. In our case, the CopyToDevice simply makes a MetalBuffer that points to the memory our data is already in. Since Macs have unified memory, no actual copying gets done here. Likewise, in the CopyFromDevice op, we’re just creating a new Vec with the buffer’s pointer. No actual copying needs to happen.Step 3: Custom ops
Certian patterns of ops are very performance intensive, so we want to swap in an efficient version for each pattern in the graph. Matmul is a good example of this. Matrix multiplication is perhaps the single most compute intensive operation in neural networks, so we want to make sure it’s done efficiently. There’s an optimized Metal matmul kernel we swap in every time we see the Broadcasted Multiply -> SumReduce pattern. Note all of this is always done by pattern matching, not by matching explicit flags. So if a model has that pattern somewhere else in another layer, it can use a matmul even if the model author didn’t realise it was a matmul!Step 4: Kernel Fusion
Now that we have all the specialized ops swapped in, we can do the fancy automatic compilation. For Metal, this involves first fusing all elementwise ops we see together into one kernel. Let’s say you have a tensora, and you want b = a.cos().exp(). Naievely we would allocate an intermediate buffer, launch a Cos kernel to do cos(a), write the output to the intermediate buffer, then launch an Exp kernel to do exp(intermediate) and write the result to an output buffer.
Elementwise fusion does away with that and generates a single kernel that does out = exp(cos(a)), so no intermediate reads and writes are needed, and only one kernel needs to be launched.
This actually is taken much furthur, fusing unary operations, binary operations, across reshapes, permutes, expands, etc. Turns out we can get very far with this idea!
Here’s an example of how many ops fusion can merge together. On the left is the unfused graph, on the right is the functionally identical fused graph:
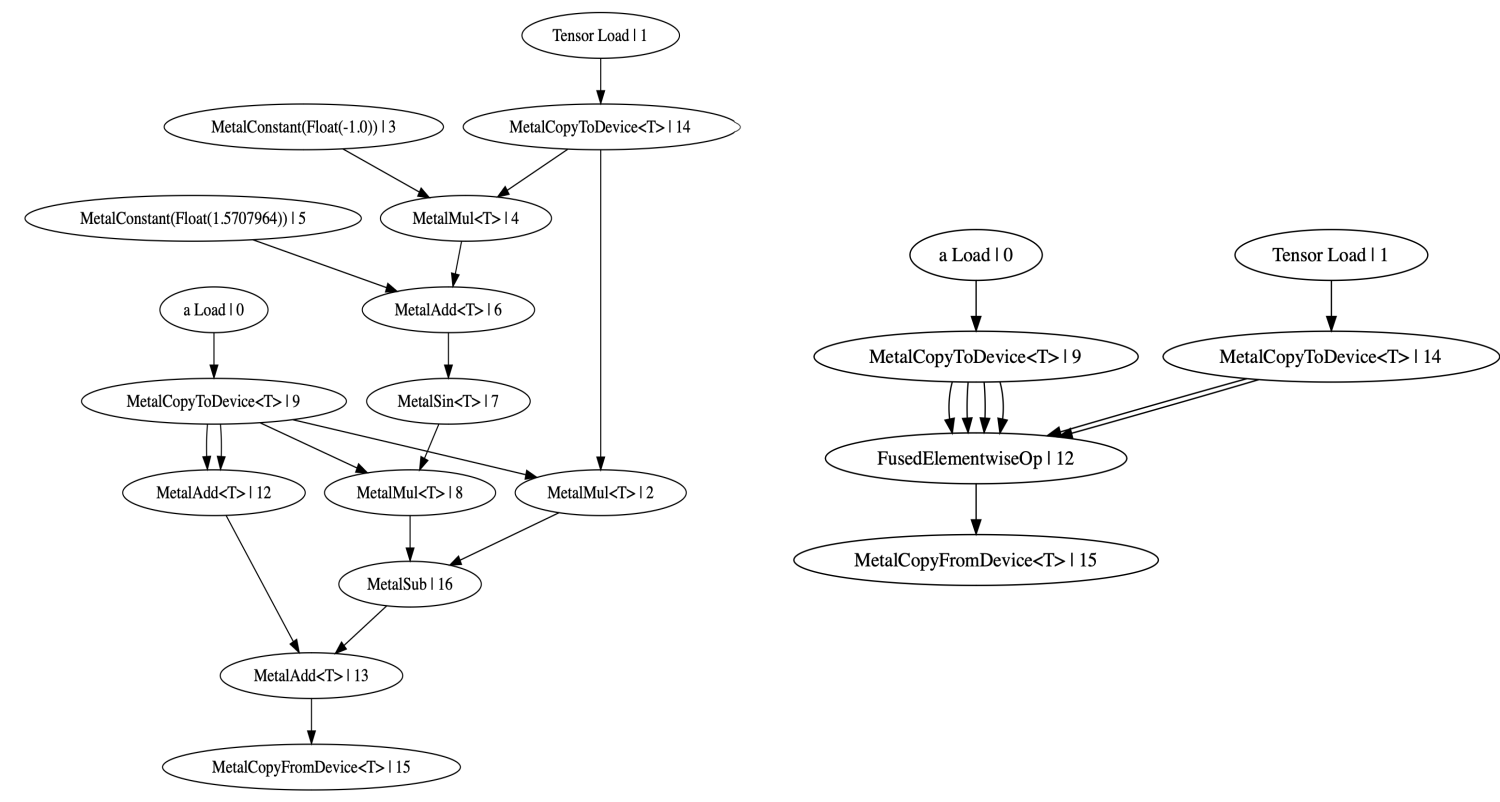
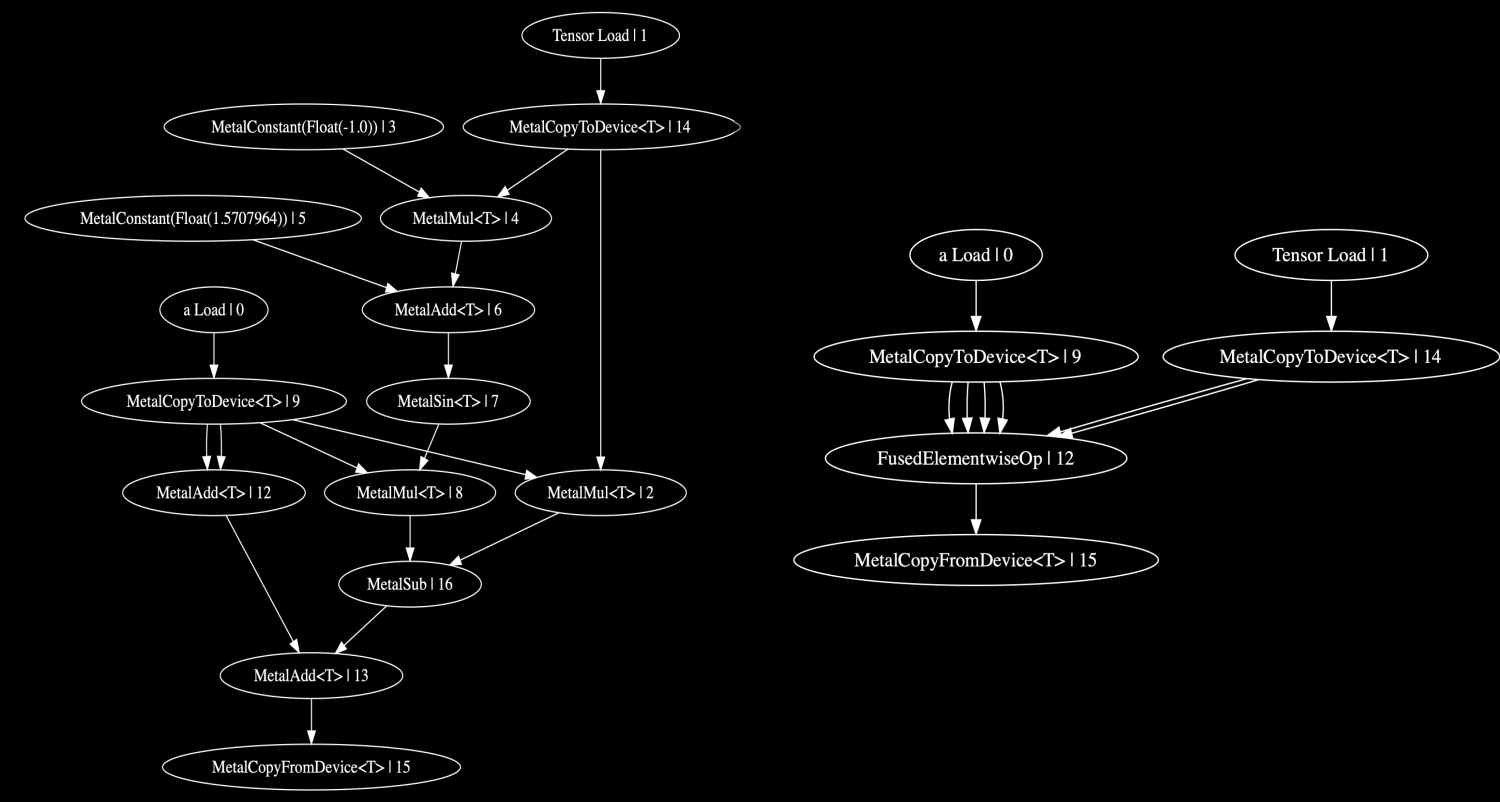
Step 5: Buffer Sharing
Storage Buffers
Since we’re reading buffers which may not be read again, it would make sense to re-use that memory directly. And since we know in advance how big all the buffers are, and when we’ll be using them, we can decide at compile time which buffers should be used where.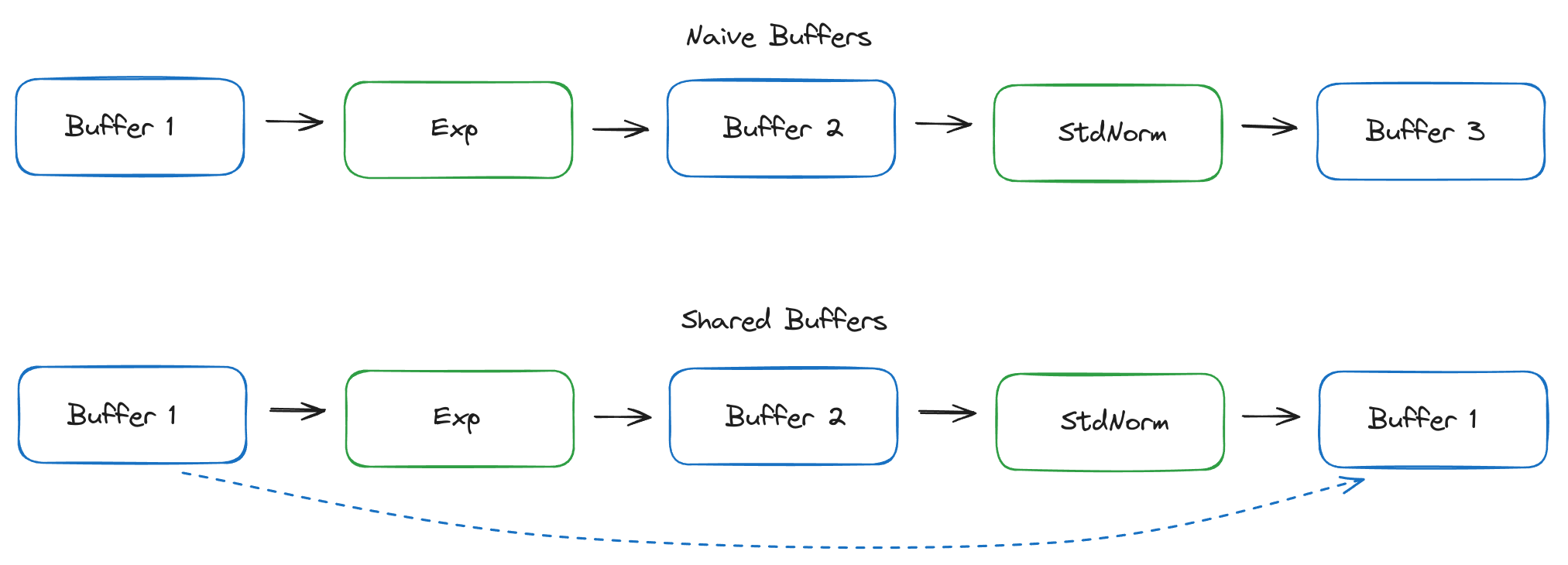
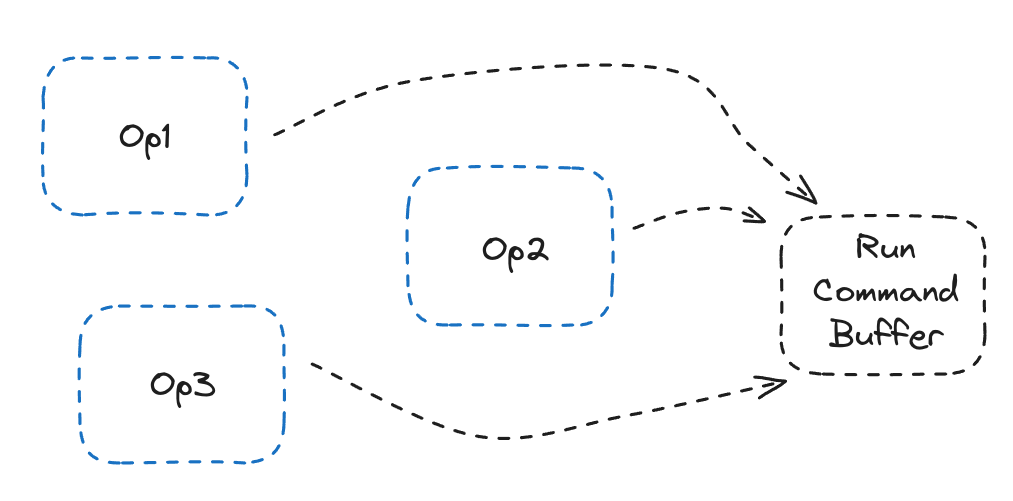
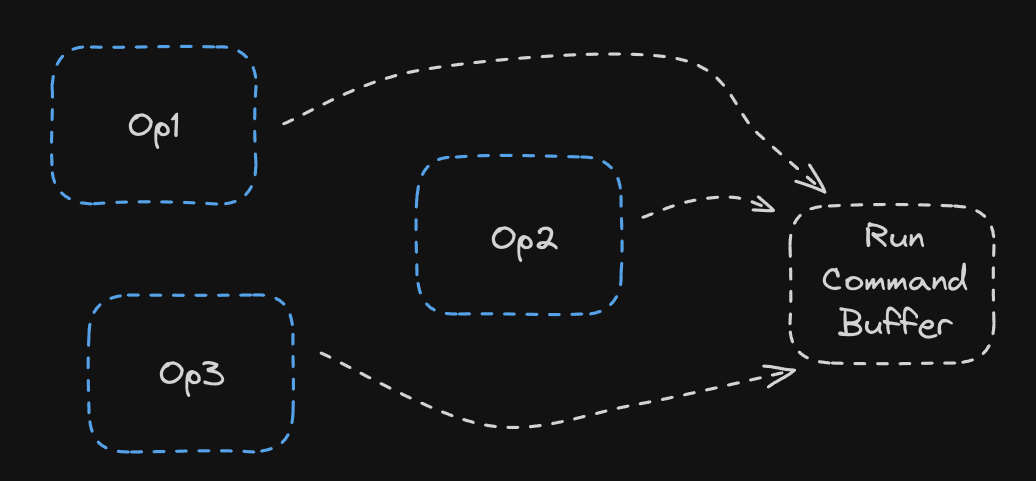
Command Buffers
Another important concept in Metal is the Command Buffer. This is where we queue all our kernels to run. Naievely we can simply run the command buffer after queueing a single kernel, and simply do that for each op we run. But running the command buffer has latency, transferring the kernel to the GPU has latency, and this is a very inefficient use of the CommandBuffer. Instead, wouldn’t it be great if we can just build a massive command buffer with all of our kernels, with inputs and outputs already set up, and just run the whole thing at once?